
数据质量
数据质量的基础
数据一致性
数据依赖性:
| 缩写 | 中文名称 |
|---|---|
| $FDs$ | 函数依赖 |
| $INDs$ | 包含依赖性 |
| $CFDs$ | 条件函数依赖 |
| $DCs$ | 否定约束 |
| $EGDs$ | 等式生成依赖 |
| $TGDs$ | 元组生成依赖 |
否定约束的形式表达:

实际例子:

元组生成依赖:

实际例子:

不同类型的依赖关系及其对应的复杂性结果:
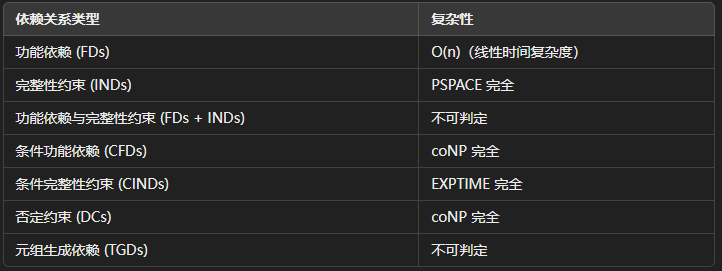
依赖关系的推理有两个经典问题:可满足性问题和蕴涵问题。


数据修复
- 数据修复
- 一致查询回答
数据修复模型:
- S-repair
- C-repair
- CC-repair
- U-repair
修复检查问题

PTIME:问题可以在多项式时间内解决,意味着计算成本相对较低。
coNP-complete:这些问题被认为是复杂且计算成本高的,尤其是对于大规模数据集。
LOGSPACE:表示问题在非常小的空间内即可解决,复杂性相对较低。
重复数据删除
数据去重
规则匹配
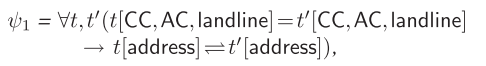

协作去重
数据修复(Data Repairing)和数据去重(Deduplication)通常作为独立的过程进行。但为了提高两个过程的准确性,建议将它们统一起来。

信息完整性
俩个世界假设:
封闭世界假设(CWA)
- 假设数据库$D$ 包含所有表示现实世界实体的元组,但某些属性值可能缺失。
开放世界假设(OWA)
- 假设数据库 $D$ 可能只是部分包含现实世界的实体,意味着元组和属性值都可能缺失。

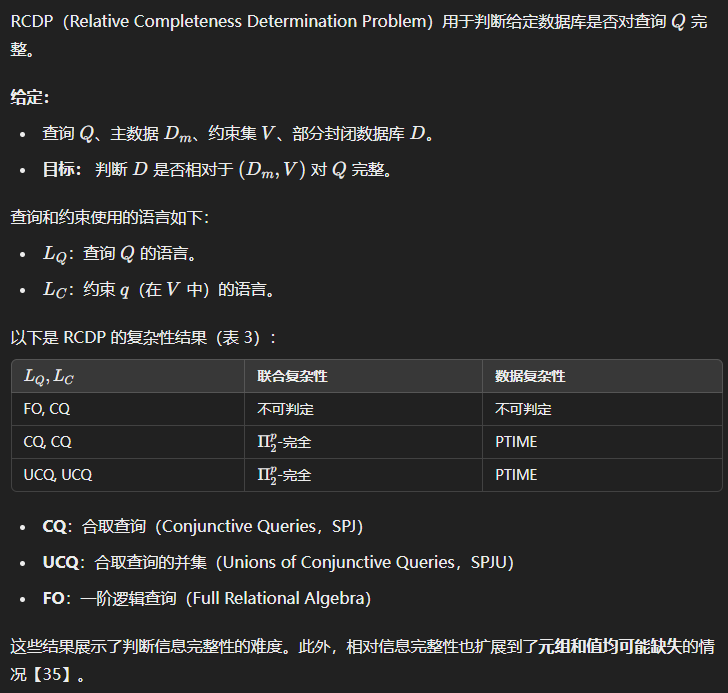
相对信息完整性问题(RCDP)
数据时效性
数据时效性(timeliness)旨在识别在一个可能过时的数据库中,元组所代表的实体的当前值,并用这些当前值来回答查询。
数据时效性建模
- 时效顺序(Currency Order)
- 时效约束(Currency Constraints)
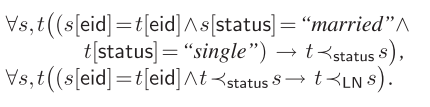
婚姻状态的变化是单向的:从“单身”到“已婚”,而不是相反。
姓氏(LN)与婚姻状态(status)相关:如果t的状态比s更当前,则t的姓氏也比s更当前。
数据时效性相关问题

数据准确性
略
数据清洗技术
- 数据分析(Data Profiling)
- 数据清理(Cleaning)
- 匹配(Matching)
发现数据质量规则
规则挖掘
为了实现规则发现,开发了一些算法
规则校验
错误检测
集中式数据库
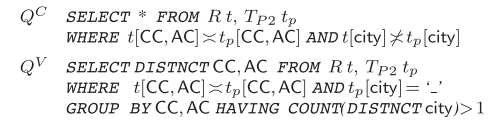
分布式数据
也有
数据修复
启发式修复
特定修复
超越数据修复
数据去重
列举了一些方法
大数据带来的挑战
- 容量(Volume)
- 并行可扩展算法
- 实体实例
- 有界增量修复
- 知识库作为主数据
- 数据动态性(Velocity)
- 数据异构性(Variety)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 CScat学习网!